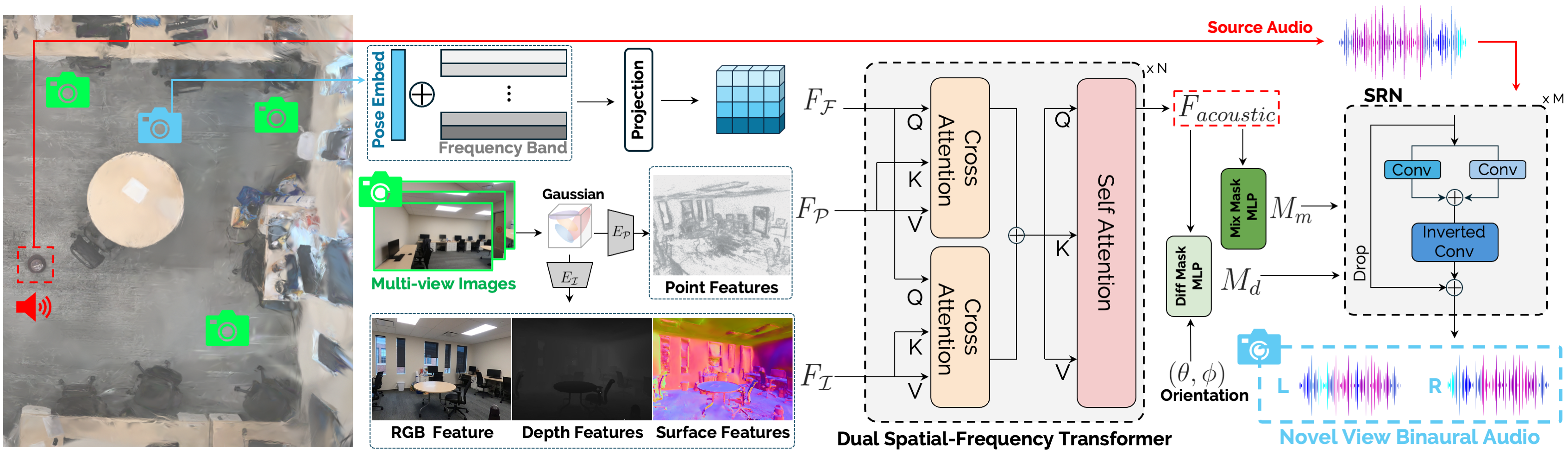
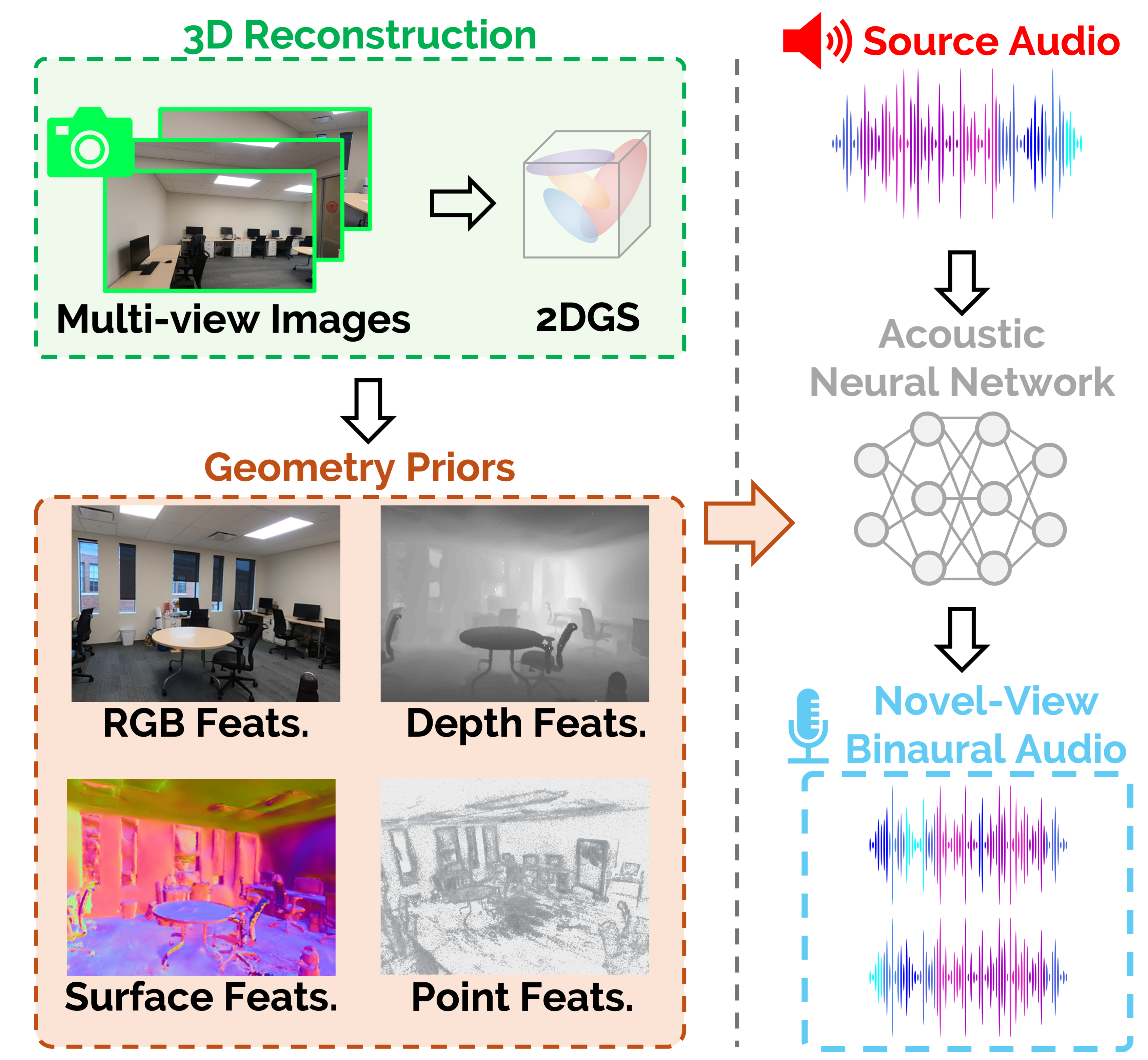
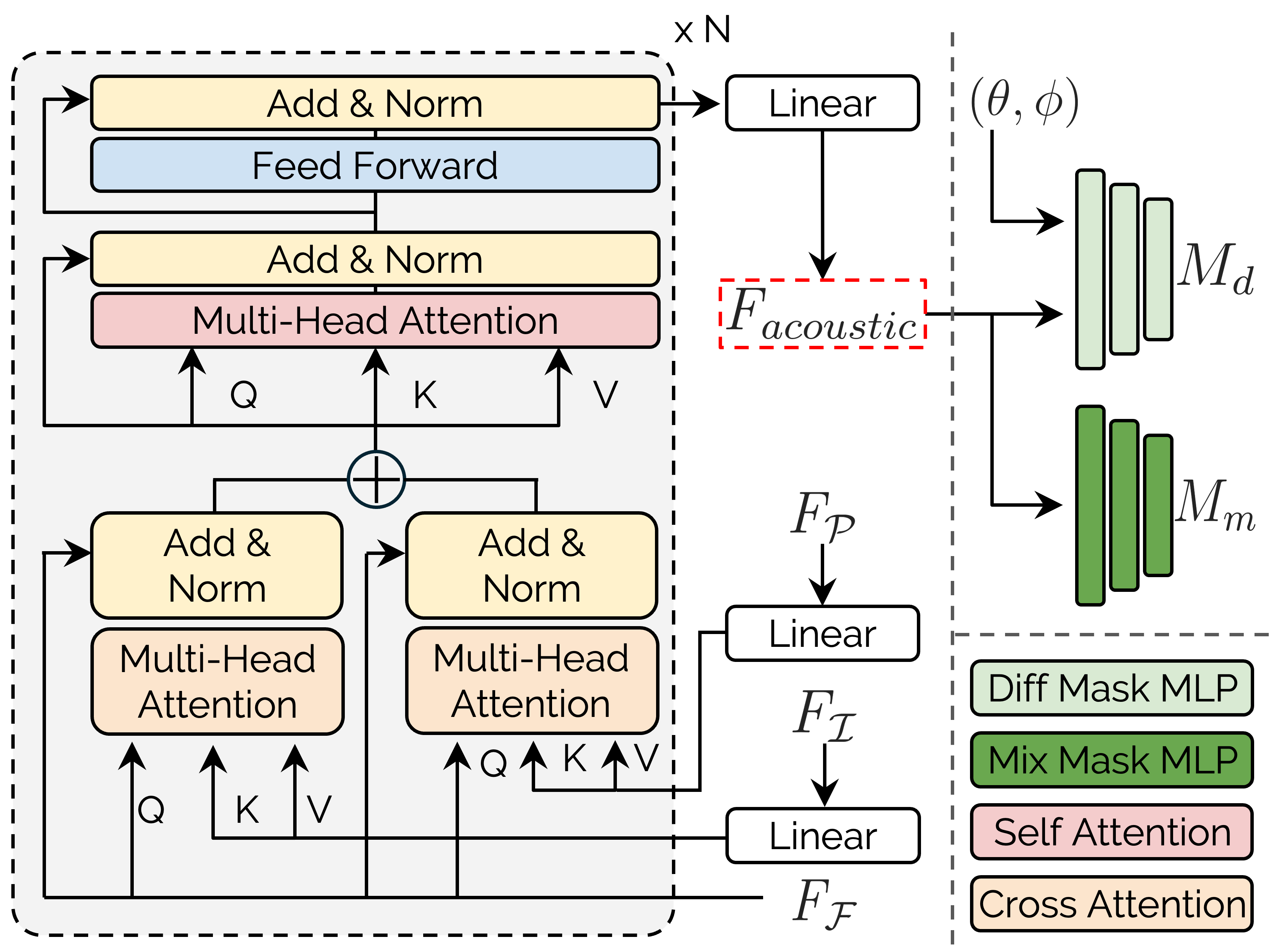
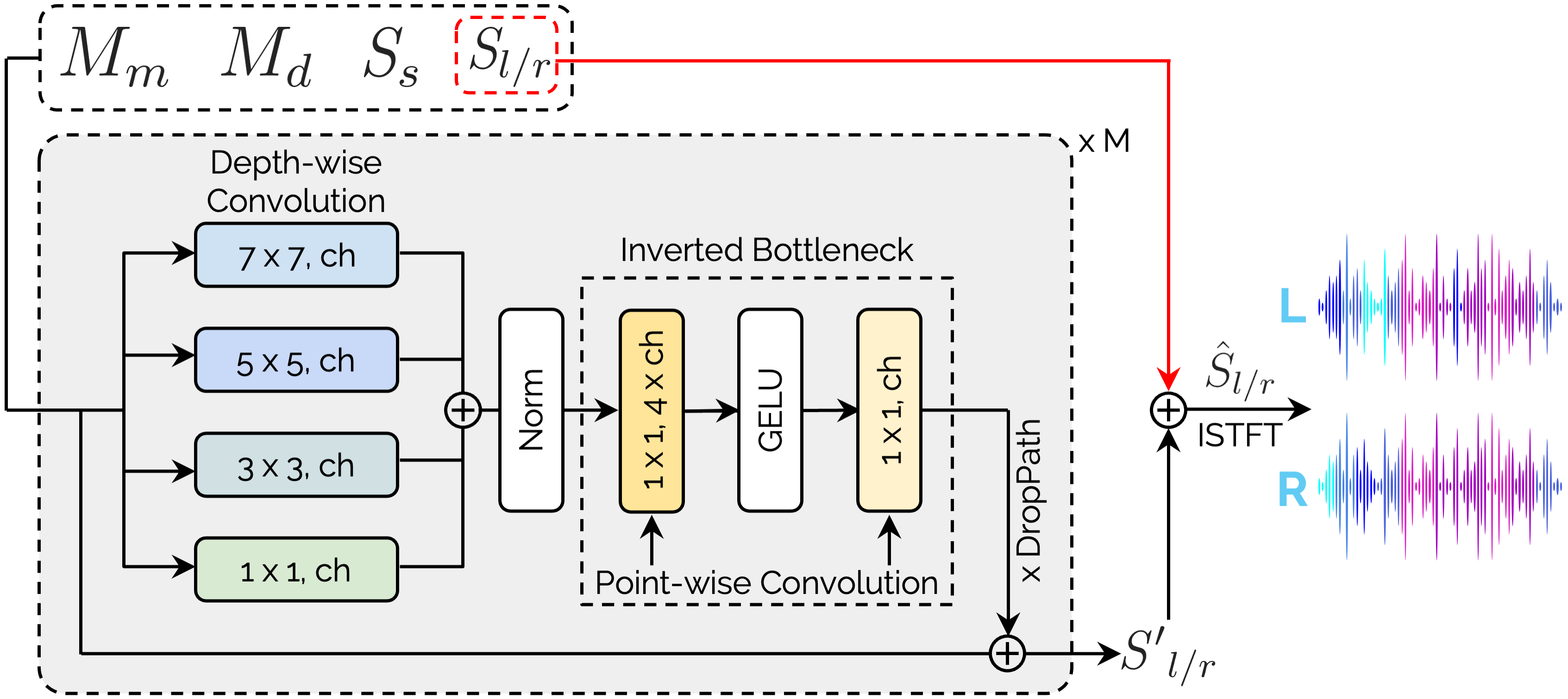
AV-Surf Overview.
AV-Surf first train 2DGS with given multi-view images to obtain various type of real-world environment information. Then we utilize two type of encoders, \(\mathit{E}_{\mathcal{P}}\) and \(\mathit{E}_{\mathcal{I}}\), to extract geometry and spatial features, \(\mathit{F}_\mathcal{P}\) and \(\mathit{F}_\mathcal{I}\). We inject spatial cues to position added frequency embeddings \(\mathit{F}_\mathcal{F}\) with iterative transformer layers to learn real world acoustics. After \(\mathit{F}_{acoustic}\) is obtained, AV-Surf follows the method from the previous study to get mixture \(\mathit{M}_m\) and difference \(\mathit{M}_d\) acoustic masks. Finally, our ConvNeXt-based decoder takes sound source and both mixture and difference acoustic masks to generate novel view binaural audio.
Model Framework
Figure 1.
Our proposed AV-Surf learns how acoustics interact with various geometry cues in the real world and uses them to predict sound source leads to binaural audio from a novel-viewpoint.
(1) Spatial-Frequency Dual Fusion Transformer
(2) Spectral Refinement Network (SRN)
We introduce AV-Surf , a novel framework for binaural audio generation designed to achieve two key objectives:
(i) integration of surface and 3D geometry priors into position-aware frequency embedding using a transformer-based architecture and
(ii) to develop spectral feature enhancing module by leveraging a ConvNeXt-based structure.
Demo Videos
We provide the demo result videos on real-world RWAVS dataset! 🔊
😊 Click the below button to change the scene 😊
Novel View Acoustic Synthesis Demo videos results
Ours
Ground-Truth
Ours
Ground-Truth
Ours
Ground-Truth
Ours
Ground-Truth
Scene rendered with NerfStudio 🎨
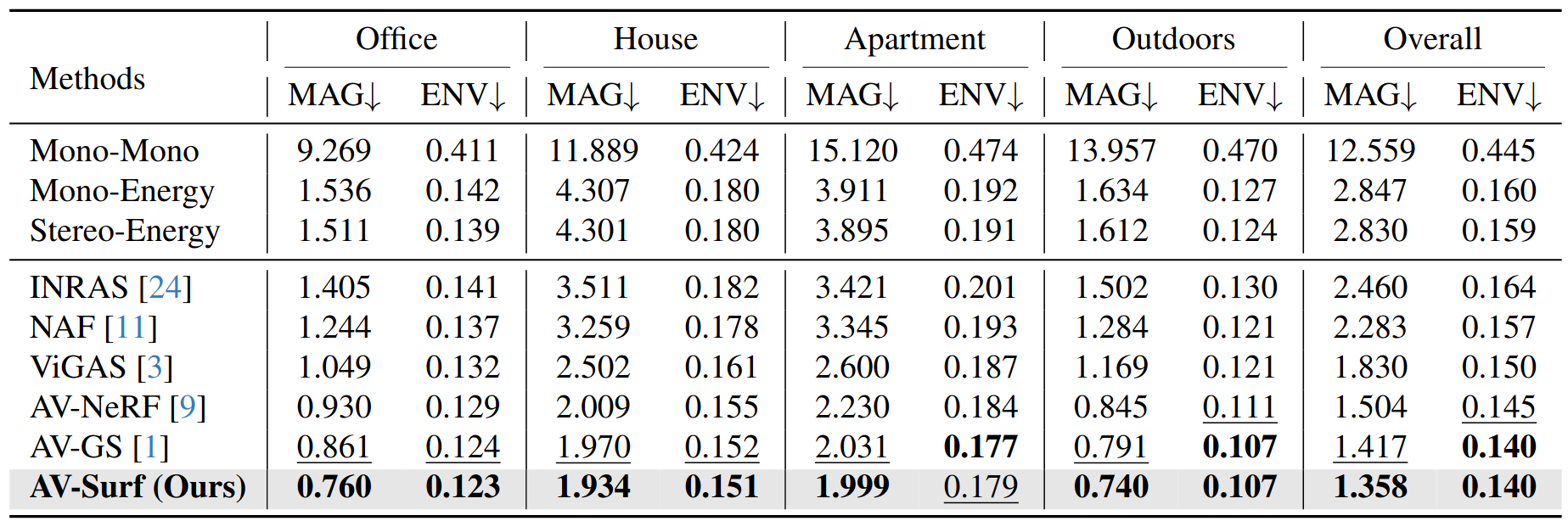
Quantitative Results
Table 1. Quantitative results on real-world RWAVS dataset. Bold indicates the best, while the second-best is underlined.